How do I re-collect a failed artifact in a hunt?
Sometimes collecting an artifact in a hunt does not work as expected.
Most commonly the issue is that the timeout or upload limit for collecting the artifact is exceeded and Velociraptor cancels the collection to prevent placing the endpoint under too much strain.
How do we work around this? We can recollect the artifact only on that failed endpoint with a few button clicks.
In the following example I will start a collection for the $MFT but
I will only set the timeout to 10 seconds and 100Mb uploaded.
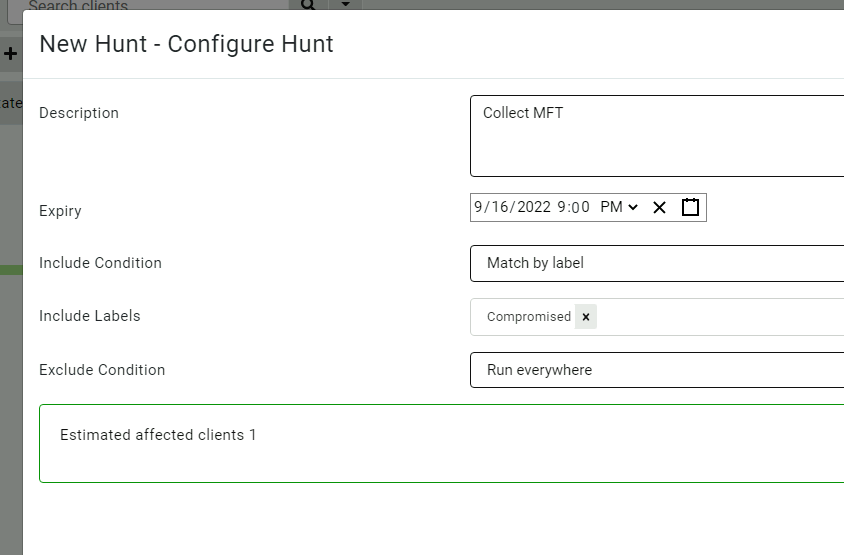
In the hunt resources screen I can specify limits for collection from any one client. These limits are intended to set reasonable boundaries for how much data I am expecting to collect so we do not overload the network or the endpoint itself.
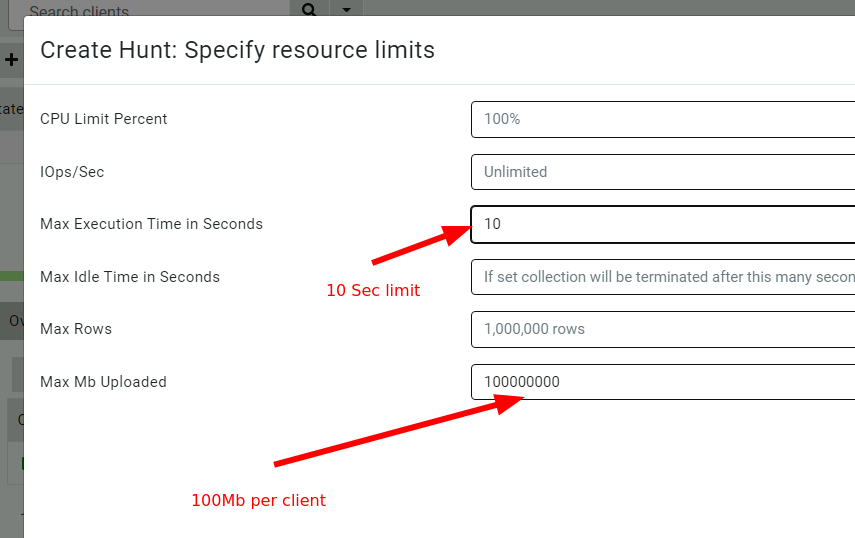
Clearly these limits are too small for this client because the collection was cancelled after 10 seconds. Normally the default timeout of 10 Minutes, but collecting such a lot of data may take longer than that.
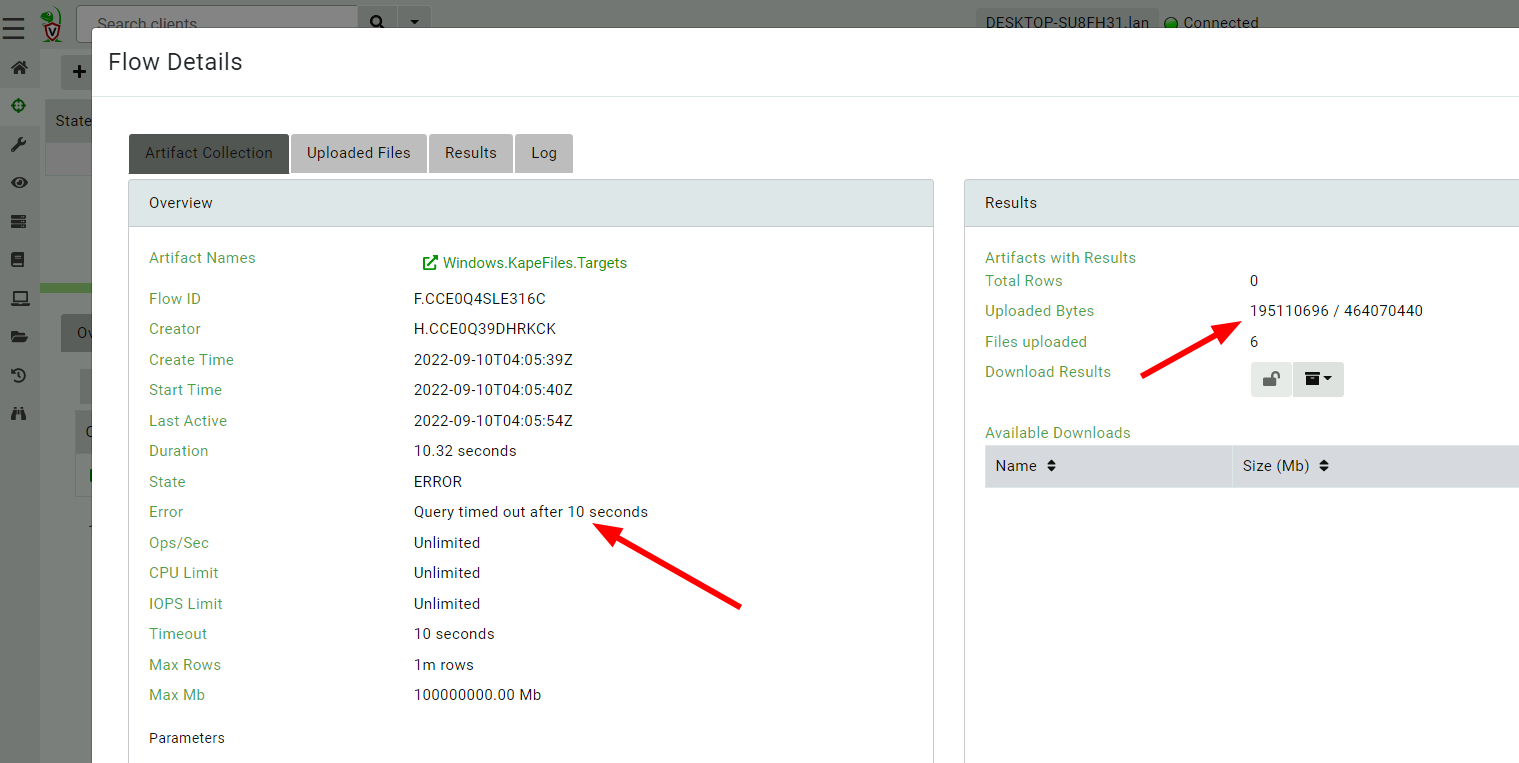
Although some data was transferred, not all the data was fully collected. This might be acceptable but if this machine is really compromised how can I recollect the same artifact?
By inspecting the collections for each client in the Clients tab, I
can quickly see which one failed.
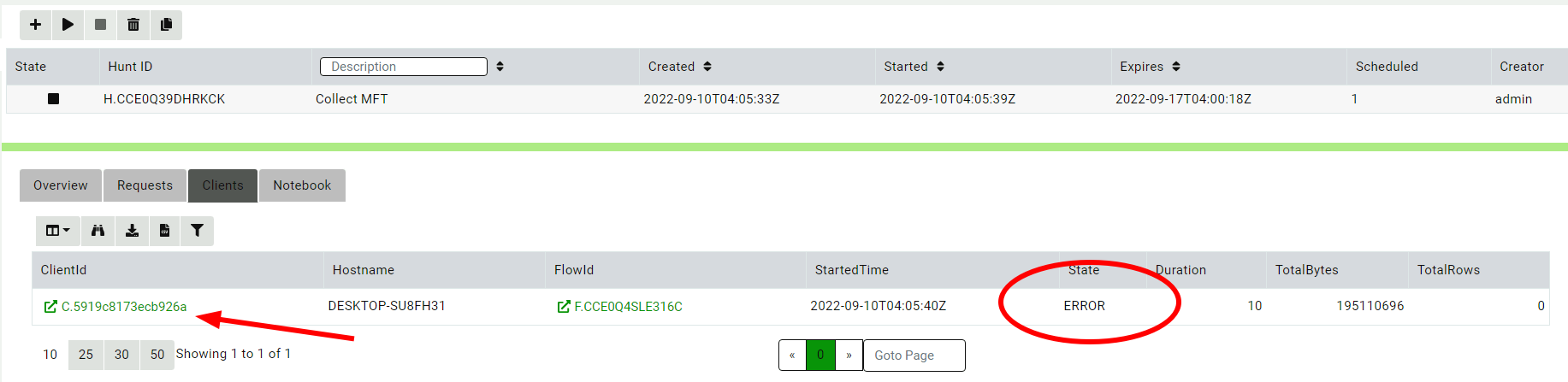
Since a hunt is just a grouping of regular collections, I can navigate to the client in the interface (by clicking the client button) and find the hunt’s collection that failed.
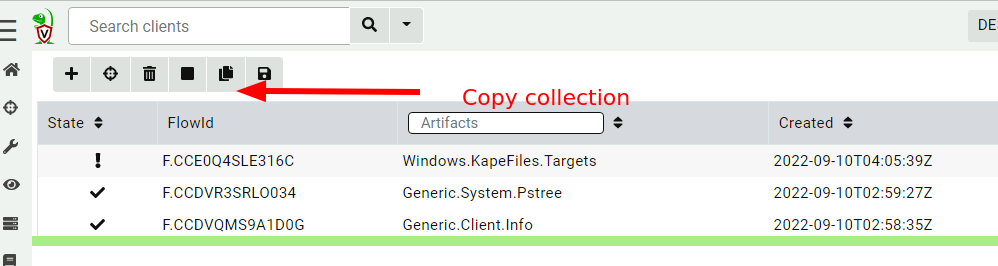
Now I just copy the collection as normal and here I can update the resource limits if needed (or maybe change some of the parameters).
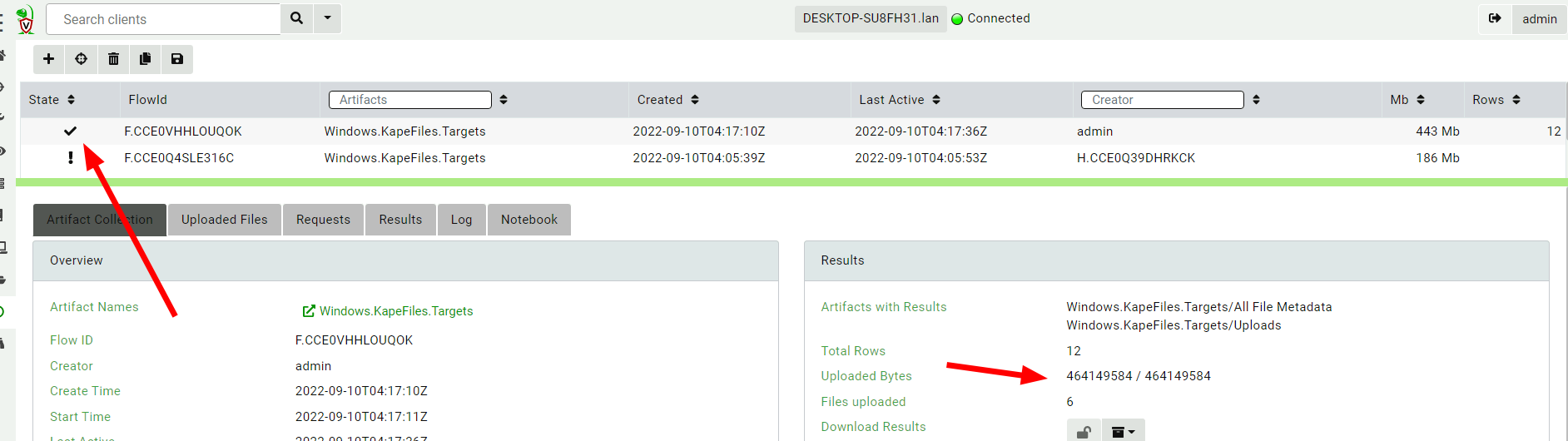
Now that this collection is completed I can just look at the results of the collections by itself or download the collection files for further analysis.
However, it is much more useful to keep all related collections in the same hunt. This helps when analyzing the hunt results in the notebook or exporting all the related files at once.
It is best to think of a hunt as just a set of related artifact
collections. You can add/remove collections from this set at will.
I am adding the new collection to the hunt manually by clicking the
Add to Hunt button.
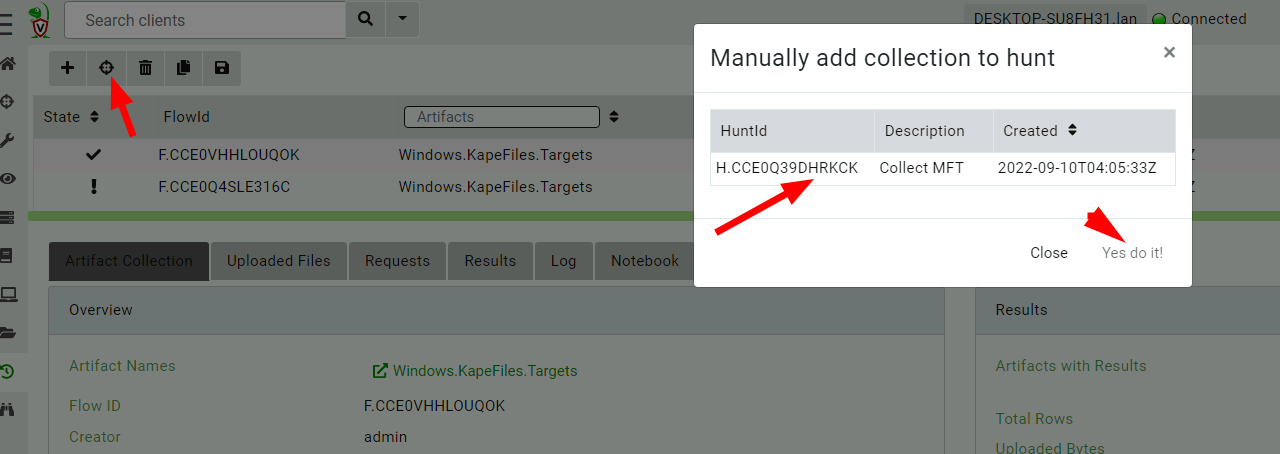
The interface shows me all hunts that collected the same artifact so I choose which hunt to add it to.
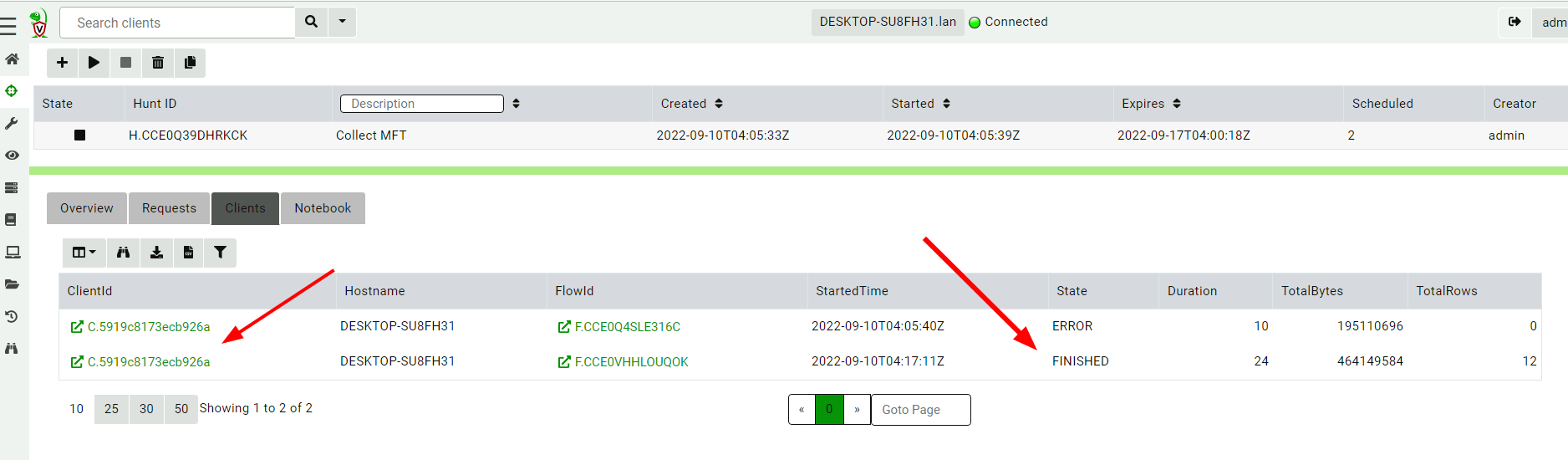
Now the new successful collection is part of the hunt. I can see it as a second entry in the client’s list.
Velociraptor does not automatically delete the old failed collection because it may still have some useful data (some data was transferred).
If you do not want the old data any more, then just click the Delete Flow button once a better collection is available.
Using VQL
The above discussion was how to manually redo collections in the GUI but if there are many collections, it might be easier to use VQL to do this.
LET NewCollections = SELECT ClientId, FlowId,
collect_client(client_id=ClientId,
artifacts=Flow.request.artifacts,
spec=Flow.request.specs,
max_bytes=1000000000,
timeout=600) AS NewCollection
FROM hunt_flows(hunt_id=HuntId)
WHERE Flow.state =~ "ERROR"
SELECT ClientId, NewCollection, hunt_add(
client_id=ClientId,
hunt_id=HuntId,
flow_id=NewCollection.flow_id) AS Hunt
FROM NewCollections
-
The
NewCollectionsquery gets all Flows in theERRORstate within a hunt and schedules a new collection using the same artifacts but increasing the maximum upload size to 1gb and timeout to 600 seconds. -
The next query adds the new collection to the hunt.
Note this query will only work after #2067