Pre-populating a server with clients, hunts and flows
When setting up a Velociraptor server for training or demonstration, it is sometimes desirable to have some data already populated.
For a realistic training exercise, some people use a Cyber Range to fully emulate a real environment. However, managing a large Cyber Range is complex and expensive.
Sometimes, we just want a simple Velociraptor server with pre-populated data, so users can learn how to analyze hunt results, and improve their VQL skills!
In Velociraptor - Everything is a file!
The Velociraptor server simply keeps all the data as simple files on disk. These files are organized into higher level concepts like Clients, Flows, Hunts and notebooks.
Conceptually you can think of these as just storage hierarchies which can be easily recreated:
-
A
Flowis a single collection that occurred as a particular time. Flows Contain artifact results, and uploaded files. -
A
Clientrepresents an endpoint. The Velociraptor server stores all flows under the client’s directory in the file store. Clients have a unique client id which is how we can identify them. -
A
Huntis a logical set of clients and flows which can be processed together using plugins likehunt_results()orsource()
Creating clients.
Normally a client will be created on the server when a physical client first connects to it. However, it is possible to create new “client” objects using the VQL client_create() function.
Let’s create 100 clients:
SELECT client_create(os="windows",
hostname=format(format="Host%d", args=_value)) AS ClientId
FROM range(end=100)
Adding flows to the clients.
Normally, we would schedule a collection on clients to gather real
data from the endpoint. But this is not essential, we can also
import an existing collection into the client’s storage space.
The existing collection can be taken on any Velociraptor instance - it is just a zip file export of a collection.
For this article, I will collect the Generic.Client.Info artifact
and export the collection into a ZIP file in the collection overview
page.
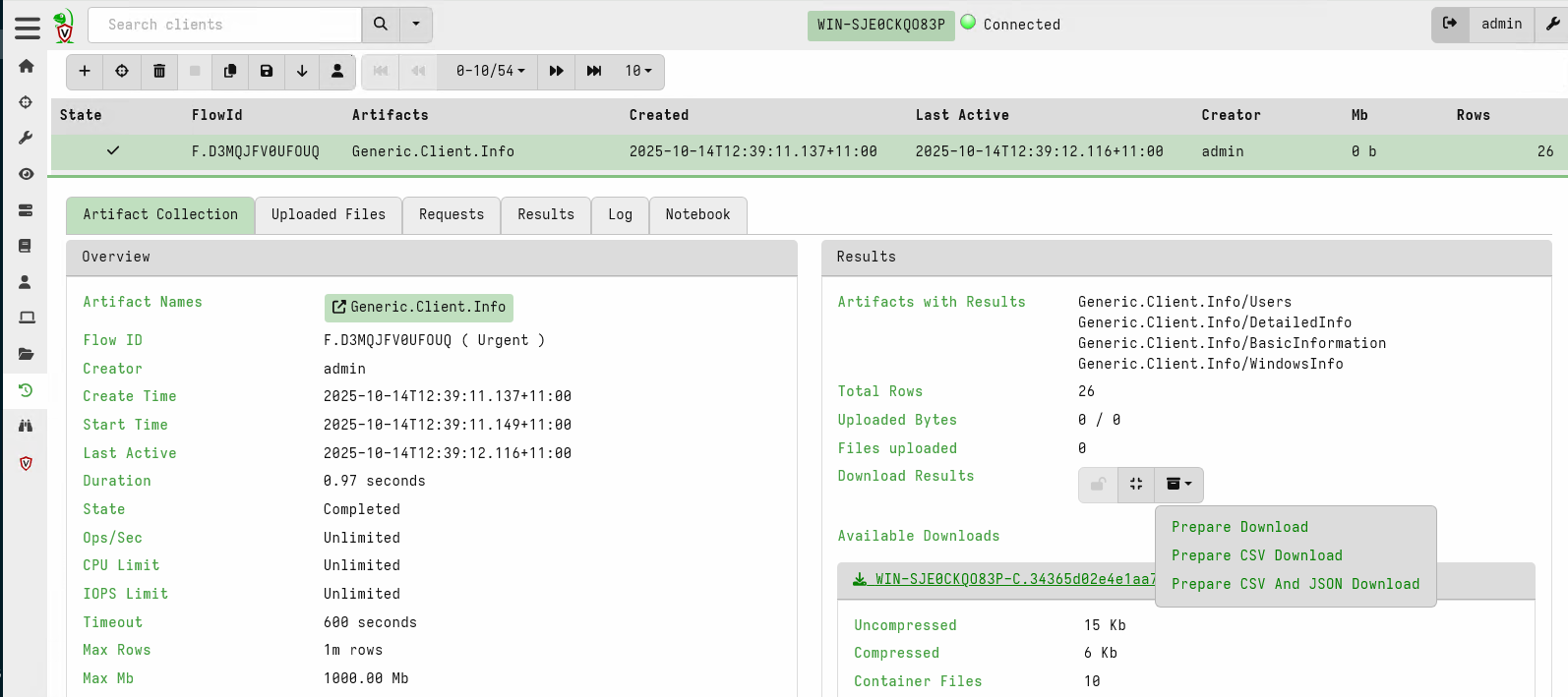
Next we import the collection into each client on the server:
SELECT import_collection(client_id=client_id,
filename="/tmp/Generic.Info.zip")
FROM clients()
Assign collections to a hunt
A Hunt is a managed container of collections. Normally we schedule a hunt so the Velociraptor server can automatically schedule flows on clients that match the hunt criteria, and keep track of these in a central location.
However, we can also just add arbitrary flows to a hunt using VQL. In
this example I will add all the Generic.Client.Info collections we
imported previously into a new hunt so I can analyze them together.
First I create a hunt using the GUI to collect the
Generic.Client.Info artifact, but I will leave the hunt in the
STOPPED state.
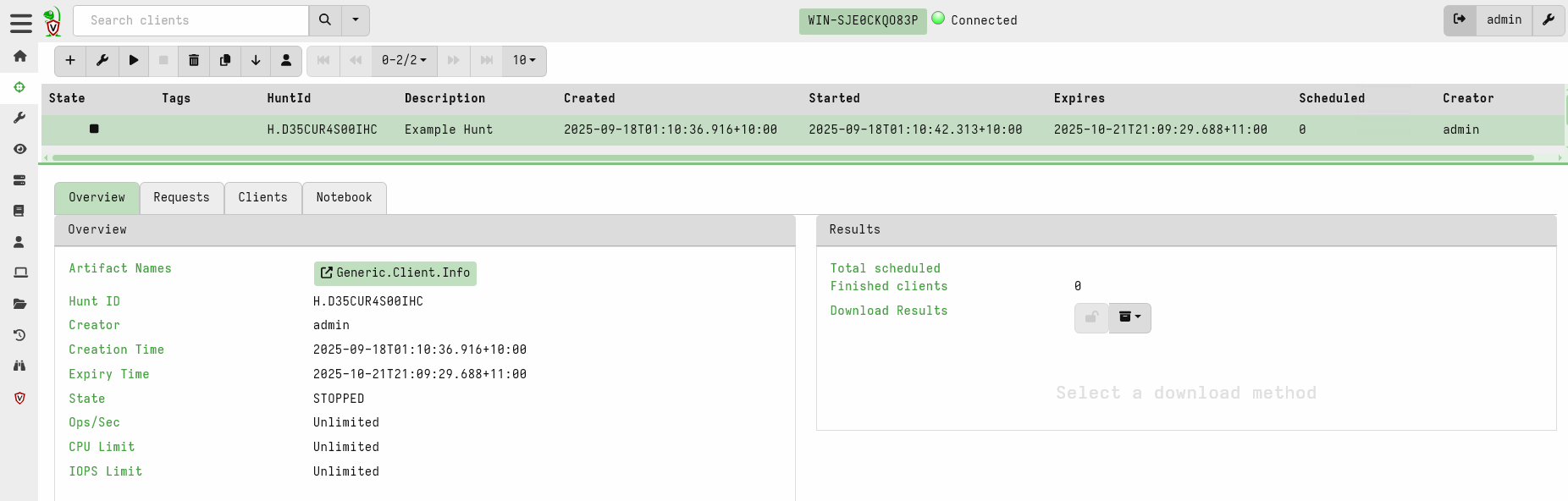
The hunt currently has no clients or flows associated with it.
I can now assign the latest Generic.Client.Info collection from each
client:
LET HuntId <= "H.D35CUR4S00IHC"
SELECT client_id,
session_id,
HuntId,
hunt_add(client_id=client_id, hunt_id=HuntId, flow_id=session_id)
FROM foreach(row={
SELECT * FROM clients()
}, query={
SELECT *
FROM flows(client_id=client_id)
WHERE artifacts_with_results =~ "Generic.Client.Info"
LIMIT 1
})
The above query:
- Iterates over all clients
- For each client, iterates over all flows in that client
- Select the first flow with artifact results of
Generic.Client.Info - After one flow matches for each client, go to the next client (this is the
LIMITclause). - Add the flow to the hunt we created earlier.
Post process the collections
Depending on the scenarios you want to demonstrate, you can create different clients (perhaps a “Compromised” set) and import different collections into them.
This method allows running any post processing steps in notebooks as if these client are real endpoints.