How to create an “online collector” binary
Velociraptor offline collectors are immensely popular with our users. They are an appealing option because of the simplicity and convenience of having a single executable file that any desktop-support-level person in a remote environment can run. The collector can then exfiltrate… oops, I mean “upload”… the collected data from the environment to a cloud storage service such as S3, GCS, Azure, etc.
Another reason why they are so popular is that many DFIR practitioners need to investigate systems in environments where there is strong resistance to installing any new software. Offline collectors do their work without installation, which overcomes that obstacle to a large degree.
So offline collectors are a great option because “it’s just an exe” and it doesn’t require any user interaction besides clicking it. It’s hard not to love that level of simplicity!
However there are downsides to offline collectors:
-
You really need to plan ahead about what you want to collect. An offline collection is often a one-shot opportunity to collect what you need. Iteration would require creating a new collector each time. By contrast a network-connected “online” client makes it easy to quickly pivot and dig deeper in response to findings.
-
Offline collectors need to be packaged with the artifacts and tools that they need. This means that you can’t quickly create a new artifact and add it to your offline collector without rebuilding and redistributing a new binary. If your artifacts need tools then bundling them into a collector binary can significantly increase the file size.
-
Because offline collectors do not provide progress updates and resource telemetry to the server, we cannot get feedback on how the collection is going or on the resource utilization.
Collections vs. File acquisitions
Many users see the word “collector” in the term offline collector and take that to mean that it’s intended to be a bulk file collector (like KAPE and many other file acquisition / triage tools). This is not the case: in Velociraptor a “collection” is the execution of any VQL on the endpoint. Velociraptor collections typically return JSON-structured data, and can optionally include file copies. But most often Velociraptor collections don’t copy files unless there’s a good reason to do so, like for preservation purposes after detecting potential evidence in the file.
Cloud-storage-in-the-middle architecture
I’ve also observed that some users will use offline collectors to upload collection data to a cloud storage service and then have their server import the collections from that storage service. If the offline collector on the endpoint can access the internet (to upload files to a cloud storage provider, for example) and your Velociraptor server is likely also accessible - or can be made accessible - from the internet then a Velociraptor client on the endpoint can probably connect the server. I suspect that sometimes this “cloud dropbox” approach might be driven more by the alluring convenience of offline collectors rather than being a sensible system architecture choice. Even if it’s somehow technically justifiable, it’s still an awfully inefficient way to do things.
Of course there may be some unusual technical constraints that force one to use cloud storage as an intermediary, but there’s also a good chance that this is being done purely because of the simplicity that the offline collector offers. And in that case the investigation is incurring delays and wasting resources by routing the data via cloud storage - even if you manage to automate the transfers.
So the question to ask yourself is: Should I really be using an offline collector?
If your offline collector can connect to a storage service on the internet then it might be worth having it just connect to your Velociraptor server via the internet. In terms of the data collected, the exact same data can be collected by a client (including files).
The Velociraptor client can be repacked to replicate the offline collector’s single-file, no-installation, “just run it” simplicity. Here’s how:
Creating an online (client) collector
Assuming that client-server connectivity is possible, you can repack a client using the same config embedding and autoexec mechanisms that offline collectors use. You can create a binary that starts in client mode and that doesn’t require installation. It can do all the same collections that an offline collector would do, with none of the disadvantages mentioned above. And all it needs is to be run locally by some suitably privileged person such as a desktop admin.
Here’s how to create and run such a client binary:
-
Download the latest Velociraptor binary for the target platform. In this case I am going to use the Windows binary for the target platform and I am going to repack it on Linux (where my binary is aliased as
velociraptor). -
Download the client config from the server Dashboard page.
-
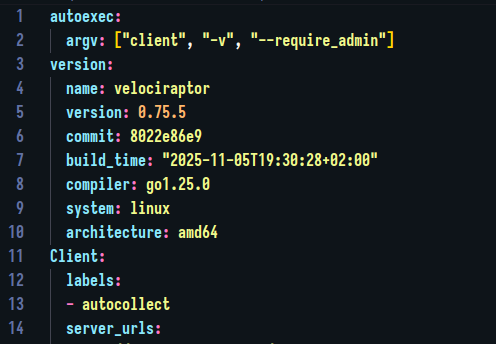
Edit the client config and add an autoexec section above the existing config:
autoexec: argv: ["client", "-v", "--require_admin"]The
-vis added so that the terminal gives some visual feedback to let the local helper who started it know that “it’s busy”.The
--require_adminis added since an installed client normally runs with elevated privileges. Offline collectors usually also enforce this requirement. -
Also add a label section to the Client section of the config - i.e.
Client.labels. This label will be used to kick off an initial hunt when the client enrolls.labels: - autocollect -
Now we do the repacking step:
velociraptor config repack --exe=velociraptor-v0.75.4-windows-amd64.exe client.root.config.yaml autocollector.exeand the results should look something like this:
... [ { "RepackInfo": { "Path": "/tmp/autoclient/autocollector.exe", "Size": 69291504, "UploadId": 0, "sha256": "398e0b37bd279f46c03508edd50649b2655516409d682fd1cd4be866b7b03bc1", "md5": "24a4cd934d91a95c72853985d2766db0", "Components": [ "autocollector.exe" ] } } ] -
On your Velociraptor server set up a new hunt targeting the
autocollectlabel.The hunt should include the same artifacts that you would have chosen for an offline collector.
Don’t forget to start the hunt!
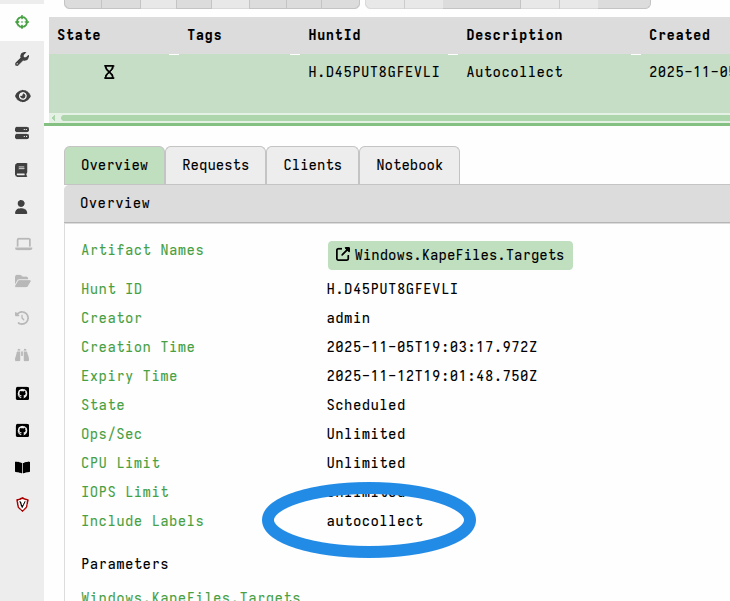
target the hunt by label (and yes, I know you still want to KAPE everything!) -
Send the
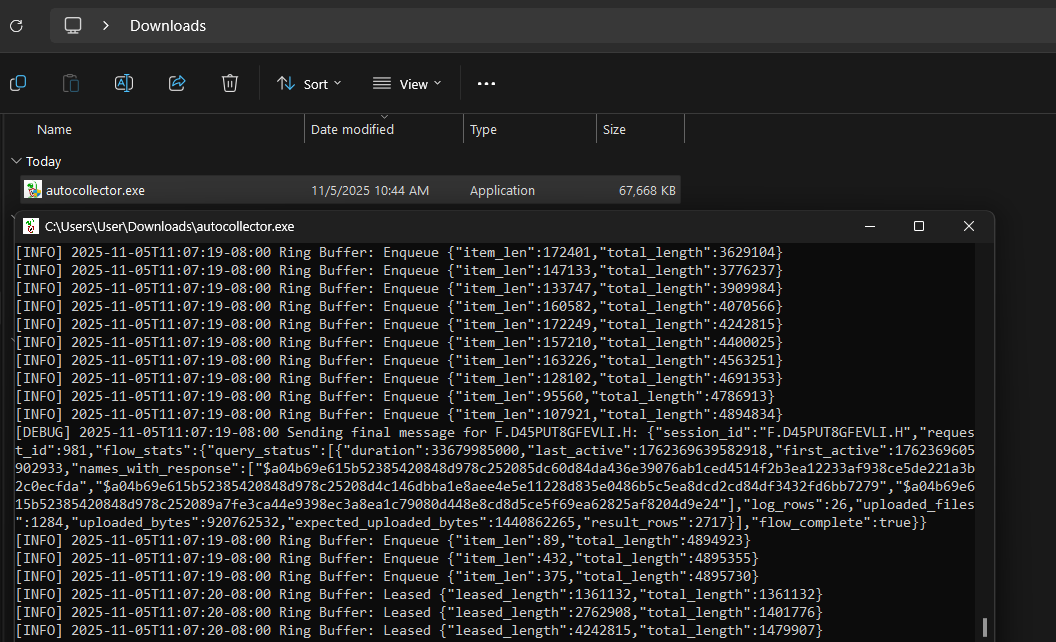
autocollector.exefile to a helpful administrator or other support staff who will run it on the machines in their environment. Tell them to ‘Run As Administrator’ and to consider the machines “busy” as long as the terminal window stays open. -
When the exe is run (as administrator) it will open a terminal window and show activity as it connects to the server, enrolls, joins the hunt, and collects the data.
-
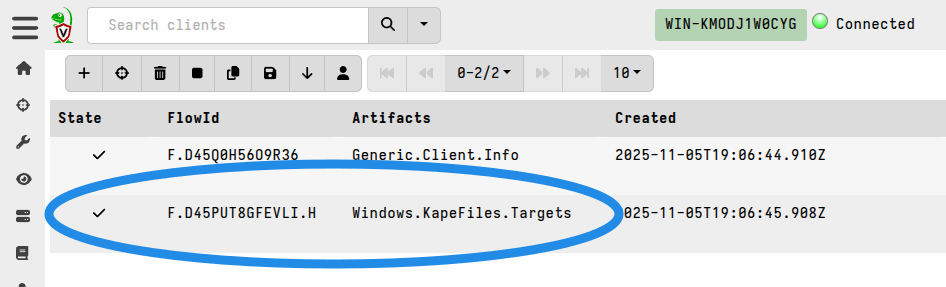
On the server the client is a normal client. You will be able to see it join the hunt and be able to view the collection results when it’s completed the hunt.
-
Now the same collection as an offline collector is completed, except that the results having been sent back directly to the server. The terminal window is still be open on the endpoint, so you are now free to do more collections as you would do with any live client, but which would not be possible with an offline collector.
-
Finally, you’ve instructed the local admins to leave the machines alone as long as the terminal windows are open. But now you’re done with a specific computer. So now you want to close the terminal on that machine to signal to the admins that it’s done.
Copy the client_id for that machine and in a global notebook and run this VQL, substituting your target client’s ID:
SELECT killkillkill(client_id="C.c6ec9a50598f590b") FROM scope()The client will be sent the kill signal and the terminal will close.
So… Online collector vs. Offline collector?
By using a non-persistent client we are able to do exactly the same collections as could be done with an offline collector, but with all the benefits of an online client and none of the disadvantages of an offline collector!
From the perspective of the helpful person running the client locally on the endpoints, there is no difference between running this or running an offline collector (with an offline collector you also should advise them to leave it alone until the terminal closes).
If your goal is to do bulk file acquisition then with this method you have all the files in your server’s datastore without the cost, hassles and delays of sending the data via a cloud storage service and then importing collection archives into the server.