Backing up and restoring a server.
Many users ask us about how to back up Velociraptor or achieve a High Availability (HA) configuration. The answer to that is nuanced and depends on exactly what data is backed up and what the end goal is.
In this article I discuss the different mechanisms and approaches used for backup and disaster recovery.
Simplest option: Re-deploy server
Let’s consider the deployment process. What if the Velociraptor server is suddenly completely gone! How can we recover?
The most difficult part of a Velociraptor deployment is the client deployment. This usually involves pushing packages to endpoints, such as an MSI or Debian/RPM packages. The process usually involves change management, approvals etc. These processes take time and so we definitely do not want to have to re-deploy clients!
Luckily the client ID is actually a property of the clients
themselves. The Velociraptor Client ID is derived from the client’s
cryptographic key and so it is not managed by the server at all -
instead it is stored on the client’s in their writeback
file. Additionally, client registration (or enrollment in
Velociraptor terminology), is done automatically the first time the
client is seen by the server.
So if the Velociraptor server is suddenly gone, we can simply redeploy the server package onto a new server and everything should work again:
-
Provision a new server VM or physical machine
-
Install the same server Debian package (which contains the same key material and configuration files).
-
Update DNS records to point to the new server IP. The clients will use these DNS records to find the new server.
-
After a short time, all clients will re-enrol and the system will become functional again.
For a successful recovery we need:
-
A backup of the server debian packages last used to upgrade the server (this will contain the server configuration file).
-
A backup of the server configuration file if it was updated since the last package upgrade.
-
A DNS record for the public interface of the server - this allows us to redeploy the server to a new IP address easily.
Restoring from daily backups
While deploying a new server gets the system operational again, it is not enough:
- Custom artifacts are not restored
- Existing hunts are not recovered
- All collected data from clients are lost
- Labels on existing clients are lost
- User accounts and ACLs are lost
- Multi-tenanted orgs are lost
To address some of these issues, Velociraptor creates a backup package daily by default. If you need more frequent backups, you can configure the backup interval in your server config using the defaults.backup_period_seconds setting.
You can also force Velociraptor to create a backup package using the VQL
backup() function, but if you do
not you can still find the scheduled (daily by default) packages in the backup
directory <filestore>/backups/. Note that the backup package in the root org
will contain all other orgs’ backups as well.
SELECT * FROM backup(name="MyBackup")
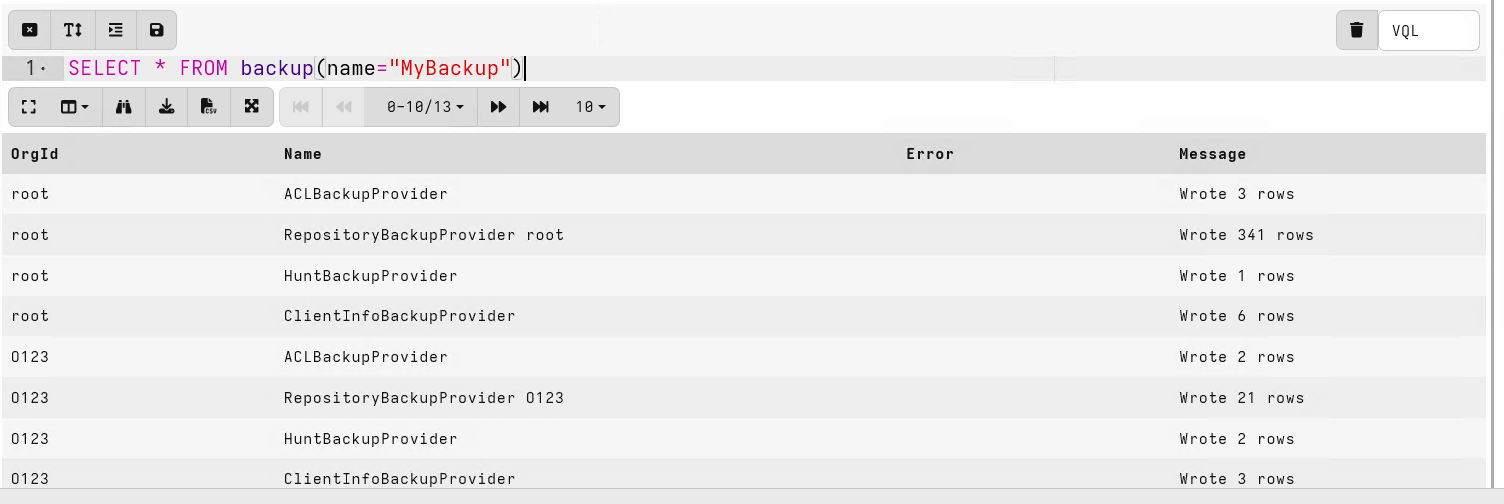
As you can see above, the backup package contains data from various
Providers. Each provider is responsible for saving some aspect of
the server’s configuration. To keep the size down, providers do not
save bulky items like collected data, rather only metadata is stored
about the server.
For example, the hunts are saved, but not the list of clients that have already provided results to the hunt (since the associated collection data is not backed up). This means that when restoring the backup on a new server, clients will participate in existing hunts again.
To restore the backup, you must copy the backup file into the backups directory on the new server.
SELECT * FROM backup_restore(name="MyBackup")
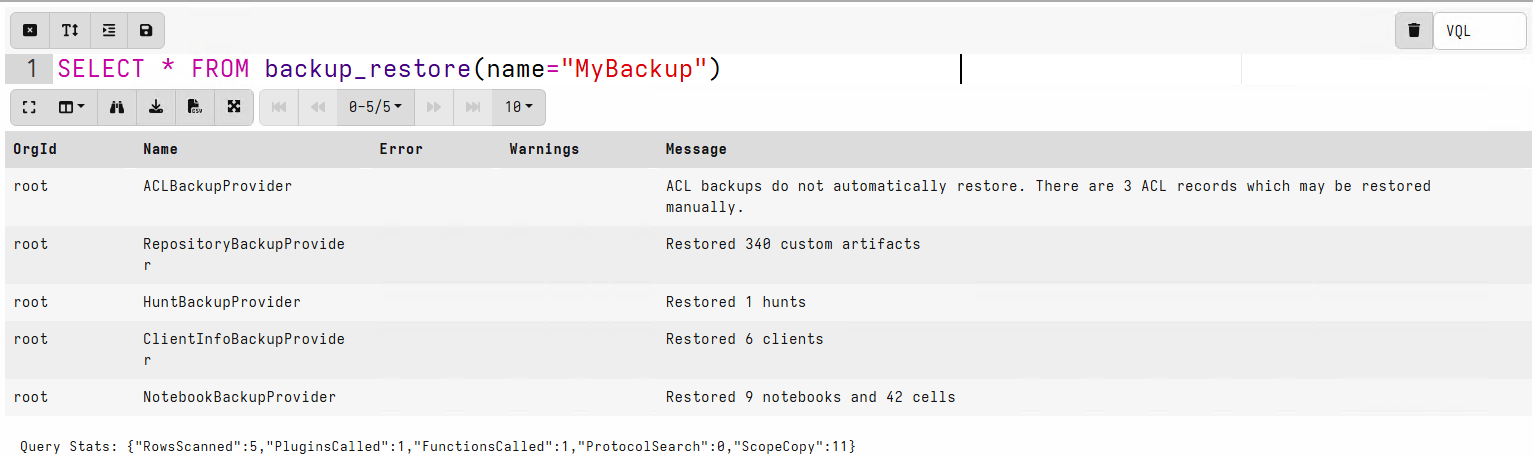
Backups always include the data from all Providers, but when restoring you can
choose a subset that you want to restore the using the
backup_restore()
providers parameter.
The current backup providers are:
ACLBackupProviderClientInfoBackupProviderHuntBackupProviderNotebookBackupProviderRepositoryBackupProvider
Note that ACL records are not automatically restored for security reasons. However you can restore them from the backup data in a Velociraptor notebook, after carefully reviewing the data. For example, this VQL would restore the users and ACLs for a specific org:
SELECT *
FROM foreach(
row={
SELECT *
FROM parse_jsonl(
filename="/tmp/extracted_backups/orgs/O123/acls.json")
},
query={
SELECT
user_create(
user=Principal.name,
orgs=Principal.orgs[0].id,
roles=Policy.roles),
user_grant(
user=Principal.name,
orgs=Principal.orgs[0].id,
policy=Policy)
FROM scope()
})
Backing up collected data
The data collected from endpoints is typically much larger and can take a while to back up. Deciding if you need that data backed up really depends on how you use Velociraptor.
Since Velociraptor is typically used to respond to incidents, the data collected is typically only useful for a short time. Velociraptor can capture a snapshot of the state of endpoints, but this data may not be relevant months or weeks later since the state of the endpoints evolve over time.
In some situations we do want to preserve the data collected from the endpoint:
-
In order to preserve evidence of compromise. This is needed to support further actions, such as disclosure or legal procedures.
-
As provenance or audit of the actions taken, what was found and justifications of further actions.
In the above use cases it is important to ensure that the data is readable outside of Velociraptor itself. For example sharing collections as generic Zip files containing CSV or JSON files is preferable to files that can only be viewed in Velociraptor.
Therefore, we really need Data Export capability from
Velociraptor. This is generated using the create_flow_download() and
create_hunt_download() plugins. Those
plugins are the equivalent of the Download Results option in the
Velociraptor GUI.
-
An export ZIP of a hunt contains all the data collected for that hunt by each client that participated.
-
An export ZIP of a collection contains all the files collected by the specific client.
For example, to archive all hunts you could use a query like:
SELECT create_hunt_download(hunt_id=hunt_id, wait=TRUE)
FROM hunts()
The VQL function create_hunt_download() will return the filestore
path you can use to read the file (with the fs accessor).
You can also upload those files to, e.g. an S3 bucket:
SELECT upload_s3(secret="S3Token",
accessor="fs",
file=create_hunt_download(
hunt_id=hunt_id, wait=TRUE))
FROM hunts()
This approach is fairly selective as you can add and remove interesting collections from certain hunts using the GUI - so in a real investigation the hunts can serve as a staging container for interesting collections.
To export specific collections, simply use the
create_flow_download() function. For example to export all
collections on the server completed in the past week:
LET OneWeek <= 7 * 24 * 60 * 60
LET DestDir <= "/tmp/exports/"
SELECT client_id,
session_id,
LastActiveTime,
copy(filename=Export,
accessor="fs",
dest=DestDir + Export.Base) AS Export
FROM foreach(row={
SELECT * FROM clients()
}, query={
SELECT *, timestamp(epoch=active_time) AS LastActiveTime,
create_flow_download(client_id=client_id,
flow_id=session_id,
wait=TRUE) AS Export
FROM flows(client_id=client_id)
WHERE LastActiveTime > now() - OneWeek
})
The above query:
- Iterates over all clients
- For each client, iterate over all flows
- If the flow is more recent than 1 week, generate a flow download.
- Copy the flow download into a destination directory, preserving the base name generated by the system (which contains the client id and flow id). Note that we need the “fs” accessor to read the download file generated.
Importing the collections into the new server
To import the collections into the new server we need to read them from the shared directory.
LET DestDir <= "/tmp/imports/"
SELECT OSPath, import_collection(filename=OSPath)
FROM glob(globs="*.zip", root=DestDir)

Complete backup of the datastore
One of the reasons Velociraptor is very easy to deploy and manage, is because everything in Velociraptor is simply a file. There is no need for complicated backend dependencies like databases - all you need to provide is a directory to store files on.
This makes it very easy to back the files up using regular backup solutions. It is perfectly safe to run incremental backups on the datastore and restore it at any time. Velociraptor does not use file locking so there is no problem with a backup software reading all files inside the data store directory.
It is possible to back up the datastore directory using rsync, a
network filesystem, or other solutions to keep a hot spare server on
standby. Then fail over is simply a matter of switching the DNS or
load balancer to the other server.
This is a more complete backup/high availability solution, but it has some caveats:
- The internal Velociraptor files are now compressed so you would typically need Velociraptor to be able to read the data.
- This type of backup solution is indiscriminate - all data is backed up regardless of how relevant it is. Storage costs can accumulate rapidly.
Conclusions
Backups, Disaster Recovery and High Availability are important aspect to consider when deploying Velociraptor. However, due to the nature of Velociraptor’s use cases, there are several nuances in how to achieve this.
By thinking carefully about what exactly we want to get out of a backup solution, what data we want to protect and how quickly we want for it to be restored we can make more informed decision about which strategy works best.
For ephemeral installations, where Velociraptor collected data is immediately exported on to other systems (for example using the Elastic or Splunk connectors), it may not be worth worrying about backups at all! A new deployment can be setup in minutes and the system can be quickly recovered.
However for most elaborate deployments, more thought can be given to backups, collection exports for preservation and maybe even a complete backup/hot standby architecture.