Design differences between Velociraptor and GRR
Velociraptor Clients run full VQL queries
GRR's design started off with the assumption that the client should be minimalist and only support a few simple primitives (such as ListDirectory, ListProcesses etc). The intention was that most of the processing would be executed on the server inside a "Flow". The main motivation for this design choice was the observation that it is difficult to upgrade the client in practice, and so with a minimal client, it would be possible to develop more sophisticated Flows, server side, without needing to update the clients.
After running GRR for a while we noticed that this design choice was problematic, since it leads to many client round trips. For example the FileFinder flow searches the client's filesystem for files by name, date etc. GRR's original file finder uses a complex algorithm to issue ListDirectory requests to the client, receive their responses, filter and recurse into directories by communicating with the client again. This leads to many round trips and has a huge performance hit on both the server and client.
Velociraptor does away with all that by including rich client side functionality (through VQL plugins), and implementing VQL queries to perform the filtering. This means that in reality, Velociraptor has very few client round trips, generally just one: The VQL query is sent to the client, and the result is received by the server.
Some types of analysis require the results of one operation to feed into the next operation. For example, suppose we wanted to upload all executables that are run from a temp directory. This requires listing all processes, then filtering the ones running from a temp directory, and finally uploading those to the server.
GRR's model requires writing a new flow for this - the flow first issues a ListProcesses request to the client, then receives all processes where the filtering happens on the server. The server then issues upload commands for each matching process. Performing this analysis requires writing and deploying new code making it difficult to adapt rapidly to changing threats.
With Velociraptor one simply issues the following VQL query:
LET files = SELECT Exe, Cmdline, Username FROM pslist()
WHERE Exe =~ '(?i)temp'
SELECT Exe, Cmdline, Username, upload(file=Exe) AS Upload
FROM files
VQL avoids this round trip completely, since VQL queries can be nested and chained together. Therefore one simply runs the first query (list all processes running from temp directory), and sends the results to the next query (download the matching files) inside the same VQL client request. It is rare that Velociraptor flows run multiple client round trips, resulting in lightweight and fast completing flows.
Worker and Database queues.
The GRR model of long running flows with multiple client/server interactions required more complex design. Since client messages can be delivered in multiple POST requests, and a single request can result in multiple responses, GRR must queue responses somewhere until they are all ready to be processed. Otherwise writing GRR flows would be difficult because one would need to account for incomplete responses.
GRR uses a complex request/response protocol to ensure messages are delivered in order, reminiscent of the TCP stack's packet reassembling algorithms.
Consider the simple request "ListDirectory". The client request may elicit thousands of responses (one for each file) and may span multiple POST operations. The GRR frontend queues all the responses in the database until it receives a STATUS response, and then fetches once. So even if the client sends the responses over multiple packets, the flow only sees a single list. When a status message is seen by the frontend, it notifies the worker via a worker queue, which collects all responses, orders them by response ID and delivers to the flow object.
This design is necessary if flows are long lived and need to handle thousands of responses for each request. However in practice this design has a couple of serious problems:
- The frontend receives responses and just writes them into the database in special queue rows, then the worker reads them from the queue rows for processing (after which they must be deleted from the database). This leads to a lot of unnecessary read/write/delete cycles and extra load on the database.
- The worker queue rows are used by all clients and all flows. This leads to a lot of database contention on these rows. Extra care must be taken to ensure no race conditions, through careful management of database locks. Extra locks slow down the database and typically for a busy system queue contention is a huge bottleneck.
This is easy to observe in practice on a busy GRR system (i.e. one that is running many flows or hunts) by simply looking at the output from top. Typically the mysql process uses as much CPU or more than the frontends and workers combined. This indicates a huge load on the database and limits scalability. Increasing the number of frontends only helps marginally because the database throughput becomes the limiting factor. In fact, increasing the number of workers can deteriorate performance because workers poll on their queues while holding locks thereby increasing row lock contention even more.
Velociraptor takes a different approach. Since Velociraptor flows are very simple and typically only consist of a few request/response cycles, the server does not bother to reorder replies that come in different packets. Therefore there is no need to temporarily store or queue responses. Responses can be delivered to the flow as soon as they are received - and flows typically just write them to the database in their final storage location.
Therefore Velociraptor does not have a dedicated worker, nor does it have database queues. The frontend itself runs the flows directly on the received packets while serving the client's poll request. This completely eliminates the need for worker queues and their associated database contention issues. Removing the worker queues eliminates a significant amount of very complex and delicate code. Additionally, since the responses are not written/read to the queue, the total load on the database is significantly reduced. (In fact because database lock contention is so low, Velociraptor can work very well with plain files through the FileBaseDataStore, even at large scale!)
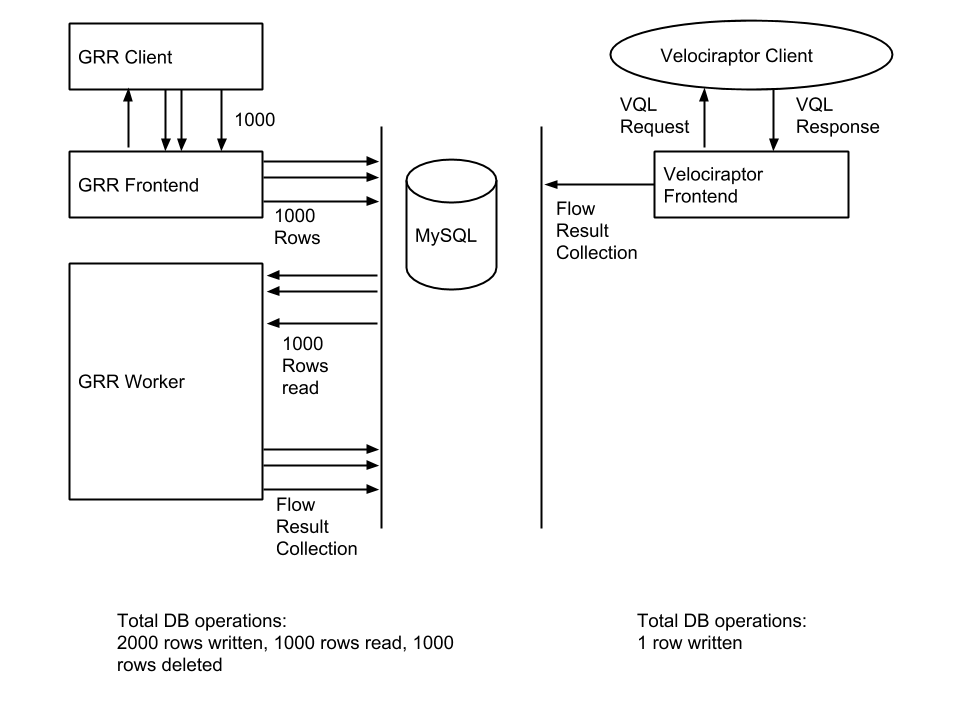
The following illustration demonstrates how significant this is for the simple example of a ListDirectory request of a directory with 1000 files in it (e.g. the c:windows directory). The equivalent VQL is select * from glob(paths='c:/windows/*') and only produces a single response packet containing all the files in the one table, whereas GRR's ListDirectory client action produces a single response for each file, which is then queued and stored independently in the database.
The overall effect, in the GRR case, is that 2000 database rows are created, of which 1000 rows are immediately deleted - a significant database load. Compare this with the Velociraptor equivalent flow -the VQL request is sent to the client once, then the response is returned to the frontend in a single POST operation. Since Velociraptor does not have a separate worker and does not need to queue messages to it, the frontend immediately runs the flow which just writes the result into a single DB row - total database operations: 1 row written.
Eliminating the need for a separate worker process also simplifies deployment significantly. GRR needs to deploy separate frontends and worker processes, and it is often difficult to know which one to scale up. Scaling up the frontend will allow more packets to be received but actually increases the load on the database. Not having sufficient workers will leave many requests on the queue for a long time and will prolong the execution of the flow since a worker must run the flow in order to issue the next set of requests. This leads to flows which take many hours to complete and even hung flows (if the client reboots or disconnects before the flow finished).
Velociraptor deployment is much simpler - there is only a single binary and it can be scaled and load balanced as needed. Since database load is much lower, the frontend can handle a much larger load. Furthermore, the flows typically execute in very short time (since there is only one round trip). The overall result is that flow throughput is much increased and resource usage is reduced.